Rust, Databend and the Cloud Warehouse(5)从 Git 到 Fuse Engine 存储引擎
/ 点击Databend 是一个使用 Rust 研发、开源的、完全面向云架构的新式数仓,致力于提供极速的弹性扩展能力,打造按需、按量的 Data Cloud 产品体验。
开源地址:https://github.com/datafuselabs/databend
前言
这篇来介绍下 Databend 底座: Fuse Engine,一个动力澎湃的列式存储引擎,Databend Fuse Engine 在设计之初社区给它的定位是:动力要澎湃,架构要简单,可靠性要高。
在正式介绍之前,我们先看一组“挑战数据”,Databend Fuse Engine + AWS S3,一个事务在 ~1.5 小时写入了 22.89 TB 原始数据:
1 | mysql> INSERT INTO ontime_new SELECT * FROM ontime_new; |
同时,在功能上要满足:
- 分布式事务:支持多个计算节点同时读、写同一份数据(存算分离架构首先要解决的问题)
- 快照隔离:不同版本数据之间互不影响,方便做 Table Zero-Copy
- 回溯能力:可切换到任意一个版本,方便做 Time Travel
- 数据合并:合并后生成新版本数据
- 简单、健壮:关系通过文件来描述,基于这些文件即可恢复出整个数据系统
从这些需求出发,你会发现 Fuse Engine 跟 Git “形似”(Git-inspired),在介绍 Fuse Engine 设计之前,我们先来看看 Git 底层是如何工作的。
Git 工作机制
Git 解决了分布式环境下的数据版本管理(data version control)问题,它有隔离(branch)、提交(commit)、回溯(checkout),以及合并(merge)功能,基于 Git 语义完全可以打造出一个分布式存储引擎。市面上也出现一些基于 Git-like 思想而构建的产品,比如 Nessie - Transactional Catalog for Data Lakes 和 lakeFS 。
为了更好的探索 Git 底层工作机制,我们选择从数据库角度出发,使用 Git 语义来完成一系列“数据”操作。
- 首先, 准备一个数据文件
cloud.txt,内容为:
1 | 2022/05/06, Databend, Cloud |
- 把
cloud.txt数据写到 Git 系统:
1 | git commit -m "Add olap.txt" |
- Git 为我们生成一个快照,Commit ID 为
7d972c7ba9213c2a2b15422d4f31a8cbc9815f71:
1 | git log |
- 再准备一个新文件
warehouse.txt
1 | 2022/05/07, Databend, Warehouse |
- 把
warehouse.txt数据写到 Git 系统
1 | git commit -m "Add warehouse.txt" |
- Git 为我们生成一个新的快照,Commit ID 为
15af34e4d16082034e1faeaddd0332b3836f1424
1 | commit 15af34e4d16082034e1faeaddd0332b3836f1424 (HEAD) |
到此为止,Git 已经为我们维护了 2 个版本的数据:
1 | ID 15af34e4d16082034e1faeaddd0332b3836f1424,版本2 |
我们可以根据 Commit ID 进行版本间的任意切换,也就是实现了 Time Travel 和 Table Zero-Copy 功能,那么 Git 底层是如何做到的呢? 方式也比较简单,它通过引入 3 类对象文件来进行关系描述:
- Commit 文件,用于描述 tree 对象信息
- Tree 文件,用于描述 blob 对象信息
- Blob 文件,用于描述文件信息
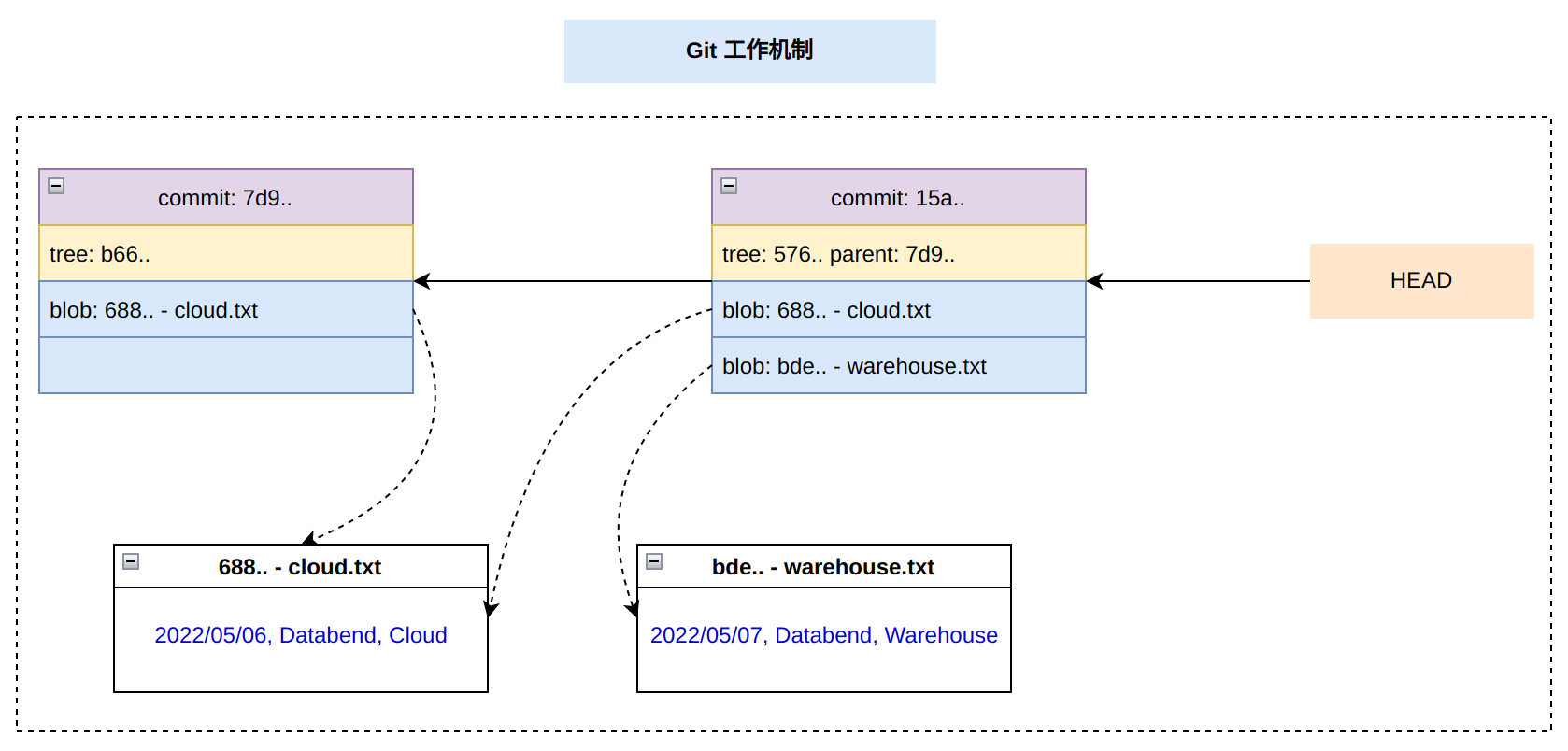
HEAD 文件
首先,我们需要知道一个 HEAD 指针:
1 | cat .git/HEAD |
Commit 文件
Commit 文件会记录跟 commit 相关的一些元数据信息,比如当前 tree 以及 parent,还有提交人等,文件路径:
1 | .git/objects/15/af34e4d16082034e1faeaddd0332b3836f1424 |
文件内容:
1 | git cat-file -p 15af34e4d16082034e1faeaddd0332b3836f1424 |
Tree 文件
Tree 文件记录当前版本下所有的数据文件,文件路径:
1 | .git/objects/57/6c63e580846fa6df2337c1f074c8d840e0b70a |
文件内容:
1 | git cat-file -p 576c63e580846fa6df2337c1f074c8d840e0b70a |
Blob 文件
Blob 文件是原始数据文件,同样可以通过 git cat-file 命令来查看文件内容(如果使用 Git 来管理代码,Blob 就是我们的代码文件)。
1 | git cat-file -p 688de5069f9e873c7e7bd15aa67c6c33e0594dde |
Fuse Engine
Databend Fuse Engine 在设计上,跟 Git 非常类似,它引入 3 个描述文件:
- Snapshot 文件,用于描述 Segment 对象信息
- Segment 文件,用于描述 Block 对象信息
- Block 文件,用于描述 Parquet 文件信息
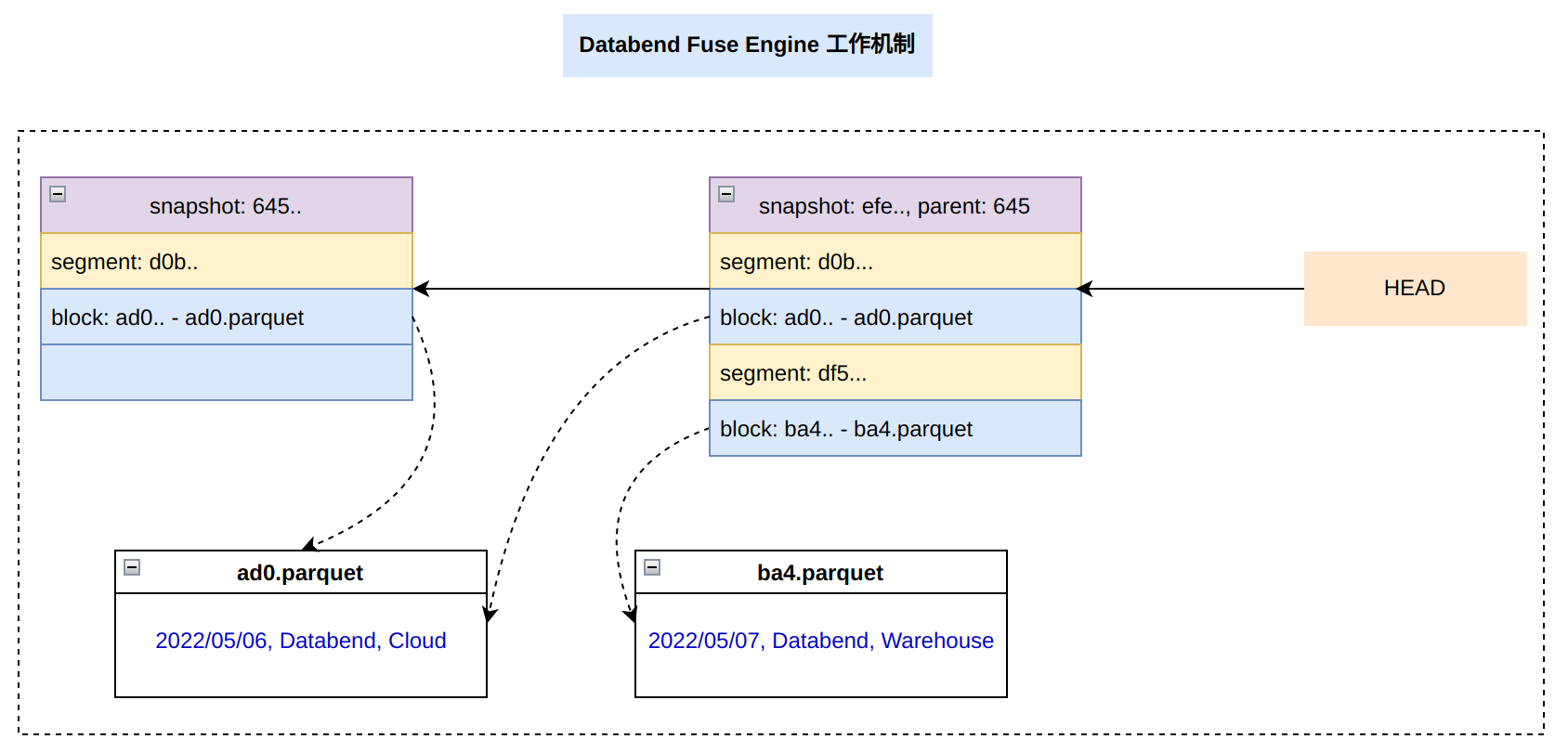
我们继续在 Fuse Engine 里进行一把刚才在 Git 进行的操作。
- 首先创建一个表:
1 | CREATE TABLE git(file VARCHAR, content VARCHAR); |
把
cloud.txt数据写到 Fuse Engine1
INSERT INTO git VALUES('cloud.txt', '2022/05/06, Databend, Cloud');
Fuse 为我们生成一个新的 Snapshot ID
6450690b09c449939a83268c49c12bb2:1
2
3
4
5
6
7
8
9
10
11
12CALL system$fuse_snapshot('default', 'git');
*************************** 1. row ***************************
snapshot_id: 6450690b09c449939a83268c49c12bb2
snapshot_location: 53/133/_ss/6450690b09c449939a83268c49c12bb2_v1.json
format_version: 1
previous_snapshot_id: NULL
segment_count: 1
block_count: 1
row_count: 1
bytes_uncompressed: 68
bytes_compressed: 351把
warehouse.txt数据写到 Fuse Engine1
INSERT INTO git VALUES('warehouse.txt', '2022/05/07, Databend, Warehouse');
Fuse Engine 为我们生成一个新的 Snapshot ID
efe2687fd1fc48f8b414b5df2cec1e19,并指向前一个 Snapshot ID6450690b09c449939a83268c49c12bb21
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18CALL system$fuse_snapshot('default', 'git');
*************************** 1. row ***************************
snapshot_id: efe2687fd1fc48f8b414b5df2cec1e19
snapshot_location: 53/133/_ss/efe2687fd1fc48f8b414b5df2cec1e19_v1.json
format_version: 1
previous_snapshot_id: 6450690b09c449939a83268c49c12bb2
segment_count: 2
block_count: 2
row_count: 2
*************************** 2. row ***************************
snapshot_id: 6450690b09c449939a83268c49c12bb2
snapshot_location: 53/133/_ss/6450690b09c449939a83268c49c12bb2_v1.json
format_version: 1
previous_snapshot_id: NULL
segment_count: 1
block_count: 1
row_count: 1目前为止,Fuse Engine 为我们生成了 2 个版本的数据:
1
2ID efe2687fd1fc48f8b414b5df2cec1e19,版本2
ID 6450690b09c449939a83268c49c12bb2,版本1是不是跟 Git 非常类似?
HEAD
跟 Git 一样,Fuse Engine 也需要一个 HEAD 作为入口,查看 Fuse Engine 的 HEAD:
1 | SHOW CREATE TABLE git\G; |
SNAPSHOT_LOCATION 就是 HEAD,默认指向最新的快照 efe2687fd1fc48f8b414b5df2cec1e19,那我们如何切到 ID 为 6450690b09c449939a83268c49c12bb2 的快照数据呢? 很简单,先查看当前表的 Snapshot 信息:
1 | CALL system$fuse_snapshot('default', 'git')\G; |
然后创建一个新表(git_v1)并把 SNAPSHOT_LOCATION 指向相应的 Snapshot 文件:
1 | CREATE TABLE git_v1(`file` VARCHAR, `content` VARCHAR) SNAPSHOT_LOCATION='53/133/_ss/6450690b09c449939a83268c49c12bb2_v1.json'; |
Snapshot 文件
用于存储 Segment 信息,文件路径 :
1 | 53/133/_ss/efe2687fd1fc48f8b414b5df2cec1e19_v1.json |
文件内容:
1 | { |
Segment 文件
用于存储 Block 相关信息,文件路径:
1 | 53/133/_sg/df56e911eb26446b9f8fac5acc65a580_v1.json |
文件内容:
1 | { |
Block 文件
Fuse Engine 底层数据使用 Parquet 格式,每个文件内部有多个 Block 组成。
小结
Databend Fuse Engine 在早期设计(2021 年 10 月)时候,需求很明确,但方案选型还是经历过一段小曲折。当时,Databend 社区调研了市面上大量的 Table Format 方案(比如 Iceberg 等),当时面临的挑战是基于现有方案还是自己造一套?最终选择研发一套简洁的、适合自己的 Storage Engine,但数据存储格式选择 Parquet 标准。
在 Fuse Engine 里,我们把 Parquet Footer 单独存放,以减少不必要的 Seek 操作,另外增加了一套更加灵活的索引机制,比如 Aggregation,Join 等都可以有自己的索引来进行加速。
欢迎体验 Fuse Engine,挂上对象存储,让你体验不一样的大数据分析 https://databend.rs/doc/deploy
Databend 开源地址:https://github.com/datafuselabs/databend
