Rust, Databend and the Cloud Warehouse (7) Using Xor Filter to Replace Bloom Filter for Faster Queries
Background
In big data analytics, many optimizations revolve around one principle: “reduce distance to the data.”
The role of a Bloom Filter Index is to probe with the index before accessing storage, then decide whether to actually read data blocks from the backend.

The Problem with Bloom Filters
Most databases you’re familiar with use Bloom Filters to handle equality queries, avoiding unnecessary data reads.
Databend’s first version (databend#6639) also used the classic Bloom Filter algorithm. Testing revealed some issues:
The Bloom Filter Index took up too much space. The index size even exceeded the raw data size (to keep things simple for users, Databend automatically creates Bloom indexes for certain data types). This meant that probing with Bloom wasn’t much different from directly reading backend data, so there wasn’t much performance gain.
The reason is that Bloom Filters don’t know the cardinality when they’re generated. For example, with a Boolean type, it allocates space based on quantity without considering cardinality (which is 2: True or False).
So the Databend community started exploring new solutions. The initial viable approach was detecting uniqueness with HyperLogLog, then allocating space accordingly.
At a TiDB user conference one Saturday in September, Databend had a booth. I met with xp (@drmingdrmer) in person (the Databend team works remotely, so meeting offline isn’t easy 😭). We discussed this problem again. He wanted to solve it using Trie concepts. The idea was good, but the complexity was high.
xp is an expert in Trie, and implementation wouldn’t be a problem for him. But I had a vague feeling that some existing technology could solve this problem well.

The Cost-Effective Xor Filter
On Sunday, I did some exploration and discovered the Xor Filter algorithm proposed by Daniel Lemire’s team in 2019: Xor Filters: Faster and Smaller Than Bloom Filters. Based on the introduction, the results looked very promising.
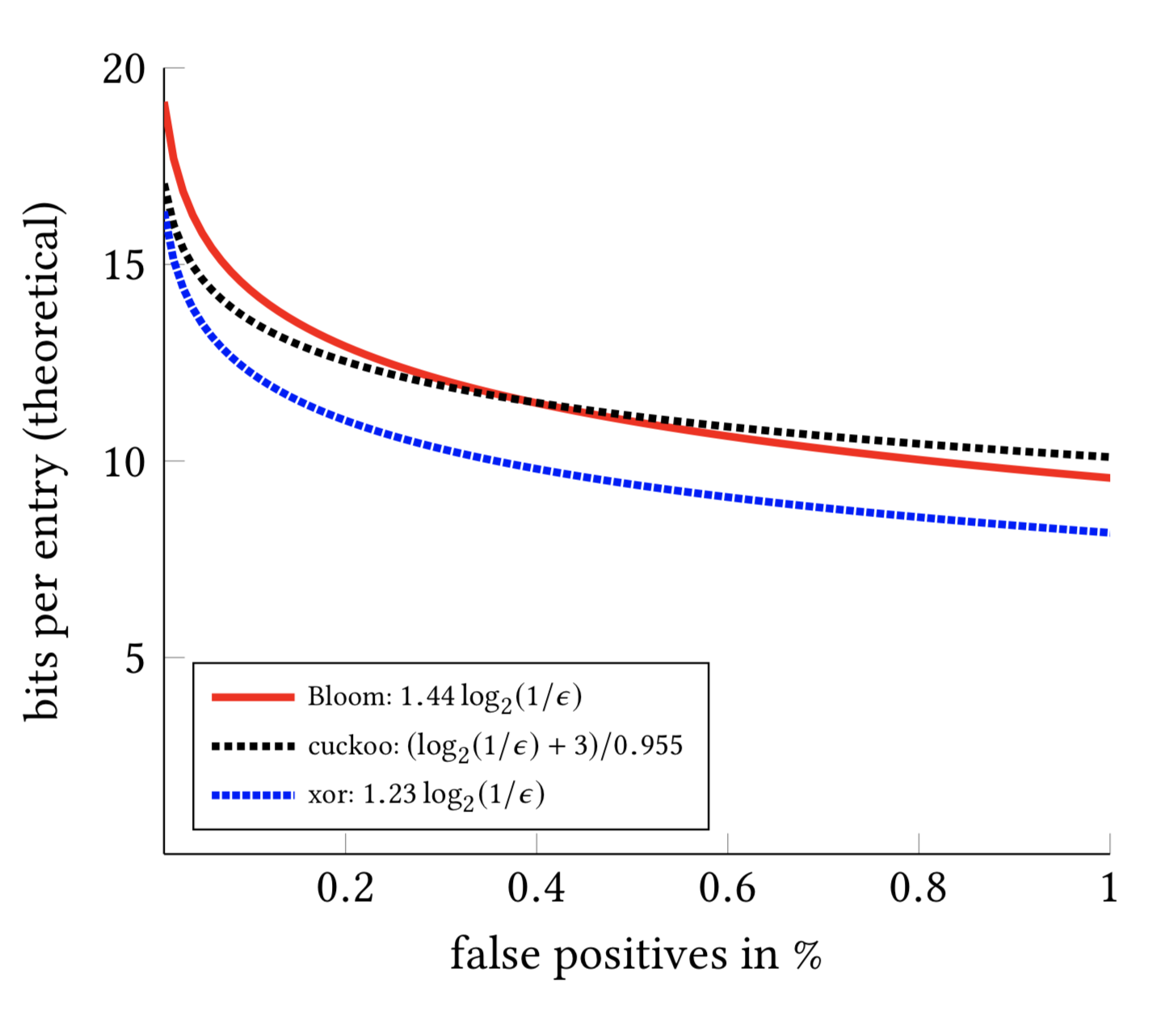
Just to try it out, I ran a test based on the Rust version (xorfilter) (Xor Filter Bench). The results were excellent:
1 | u64: |
So in databend#7860, I implemented the switch from Bloom Filter to Xor Filter. Let’s run some tests to see the results.
Test Environment
Databend: v0.8.122-nightly, single node
VM: 32 vCPU, 32 GiB (Cloud VM)
Object Store: S3
Dataset: 10 billion records, 350GB raw data, 700MB Xor Filter Index, both index and data persisted to object storage
Table schema:
1 | mysql> desc t10b; |
Deploying Databend
Step 1: Download the installer
1 | wget https://github.com/datafuselabs/databend/releases/download/v0.8.122-nightly/databend-v0.8.122-nightly-x86_64-unknown-linux-musl.tar.gz . |
After extraction, the directory structure:
1 | tree |
Step 2: Start Databend Meta
1 | ./bin/databend-meta -c configs/databend-meta.toml |
Step 3: Configure Databend Query
1 | vim configs/databend-query.toml |
1 | ... ... |
For detailed deployment docs, see: https://databend.rs/doc/deploy/deploying-databend
Step 4: Start Databend Query
1 | ./bin/databend-query -c configs/databend-query.toml |
Step 5: Build the Test Dataset
1 | mysql -uroot -h127.0.0.1 -P3307 |
Generate 10 billion test records (took 16 min 0.41 sec):
1 | create table t10b as select number as c1, cast(rand() as string) as c2 from numbers(10000000000) |
Query (no caching, data and index entirely in object storage):
1 | mysql> select * from t10b where c2='0.6622377673133426'; |
A single-node Databend, using filter pushdown and Xor Filter indexing, can perform point queries on 10 billion randomly generated records in about 20 seconds.
You can also leverage Databend’s distributed capabilities to speed up point queries. Databend’s design philosophy is elastic compute scaling on a single copy of data. Expanding from a single node to a cluster is very simple: Expanding a Standalone Databend.
References
[1] Arxiv: Xor Filters: Faster and Smaller Than Bloom and Cuckoo Filters
[2] Daniel Lemire’s blog: Xor Filters: Faster and Smaller Than Bloom Filters
[3] Databend, Cloud Lakehouse: https://github.com/datafuselabs/databend
