Rust, Datafuse and the Cloud Warehouse (1) Cloud-Era Data Warehouse Architecture Design
Traditional data warehouse architecture isn’t suited for the cloud?
What problems does a Cloud Warehouse solve?
What should a Cloud Warehouse architecture look like?
With these questions in mind, let’s embark on a practical journey toward Cloud Warehouses.
Sharding Warehouse
First, let’s look at the traditional Sharding Warehouse architecture and its limitations in the cloud.
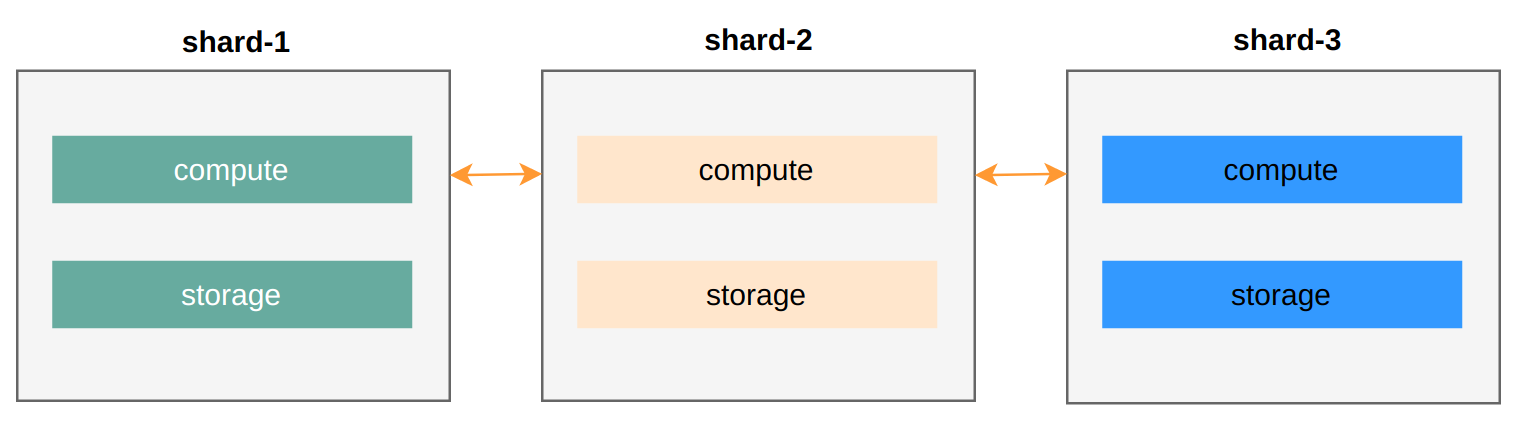
Each shard’s data range is fixed, making data hotspot (data skew) issues common. Typical solutions:
① Upgrade that shard’s hardware. If hotspots are hard to predict, the entire cluster configuration needs upgrading — coarse-grained resource control.
② Scale out. The scaling process (adding shard-4) involves data migration. If the data volume is large, the wait time before shard-4 becomes available also lengthens.
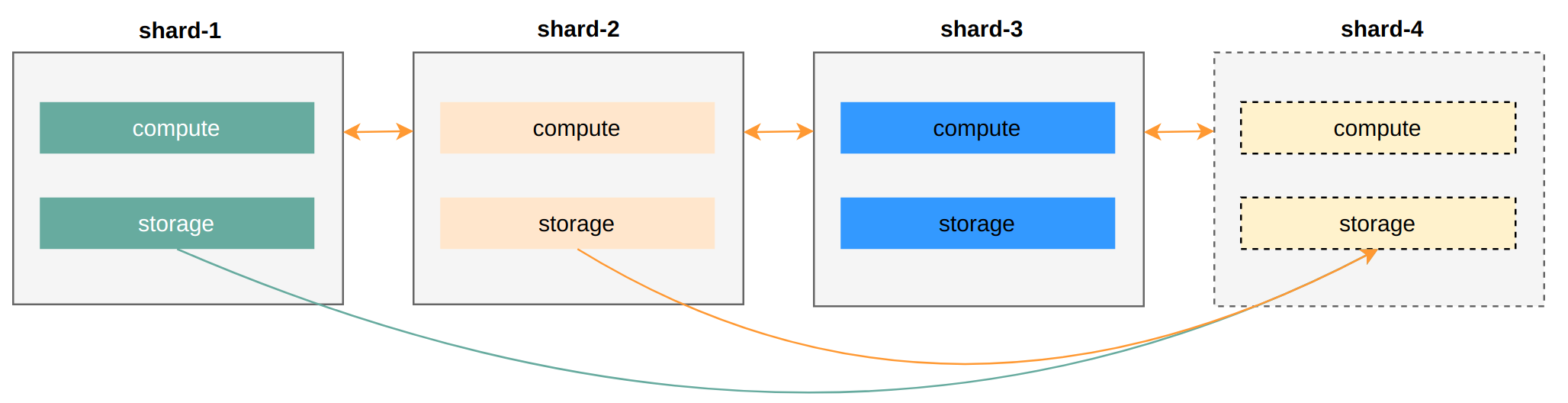
Simply moving a Sharding Warehouse to the cloud doesn’t improve resource control granularity — it’s still crude, making fine-grained control difficult and preventing accurate on-demand, pay-per-use billing.
In other words, even though we can scale arbitrarily, the cost remains high.
Cloud Warehouse
If a Cloud Warehouse satisfies:
- On-demand elastic scaling
- Fine-grained, pay-per-use resource control
What should its architecture look like?
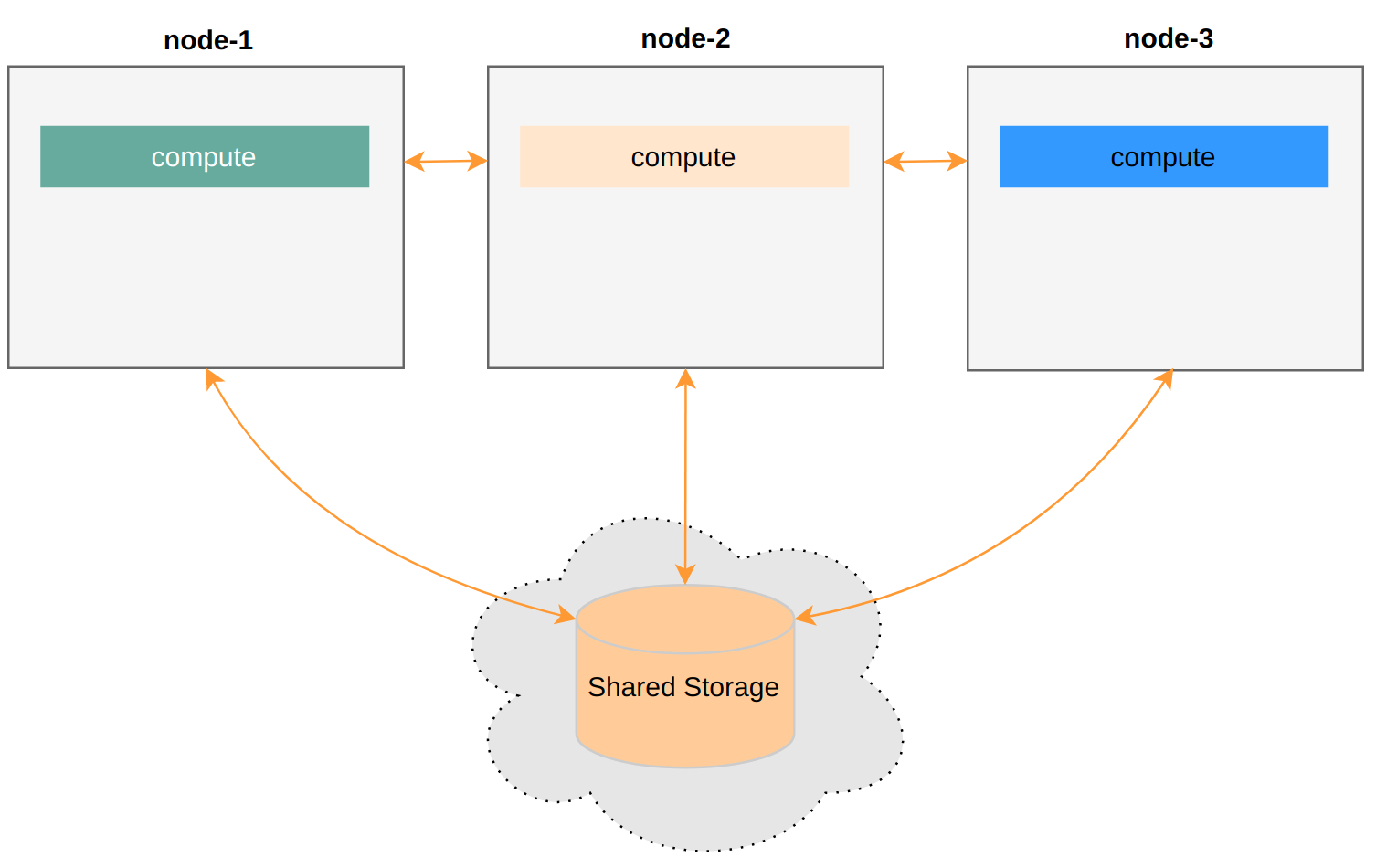
First, it’s a storage-compute separation architecture. Second, compute nodes should be as stateless as possible. This lets us add/remove compute nodes as needed. Compute power can increase or decrease smoothly without data migration.
node-4 is basically serverless — think of it as a process that automatically dies when done. This allows for much finer-grained scheduling.
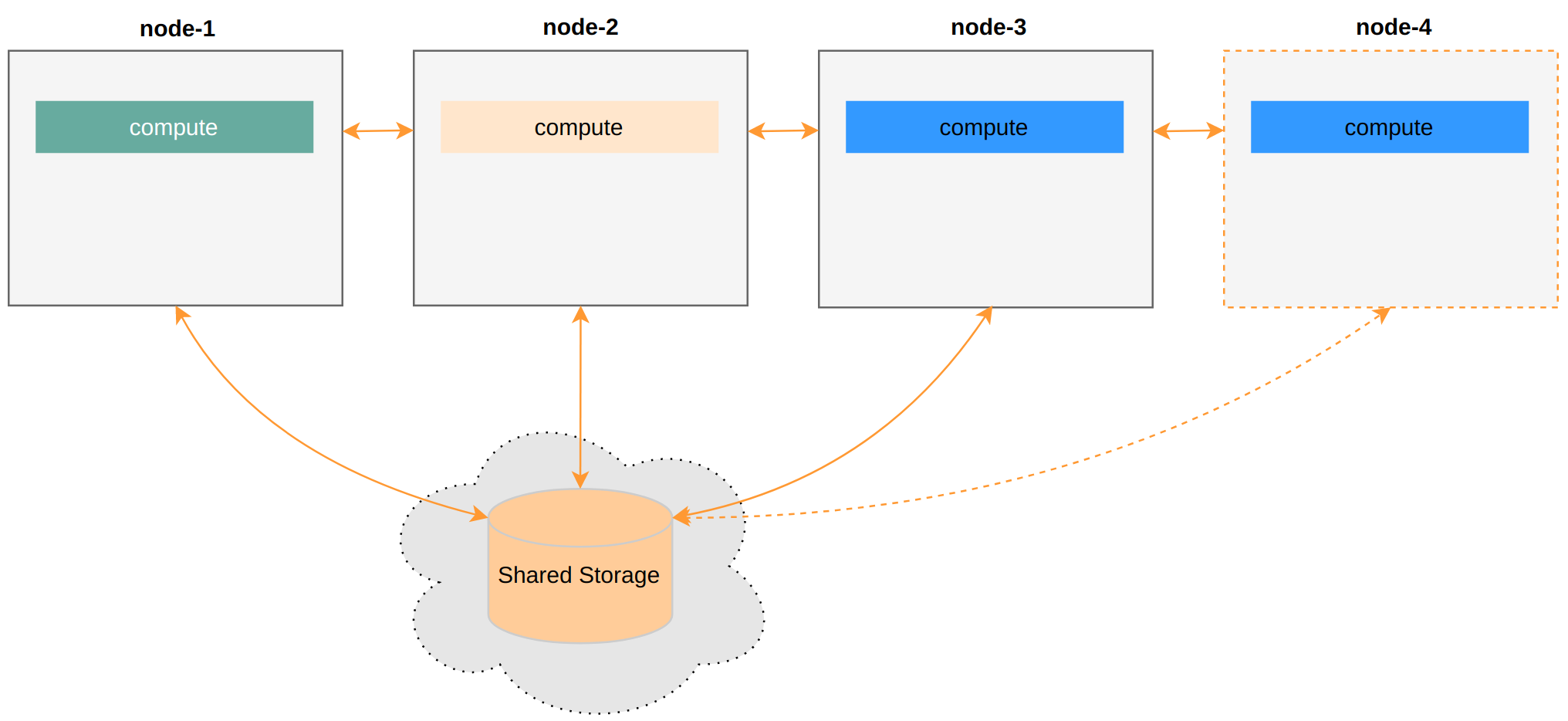
Seeing this architecture, you might wonder:
The Cloud Warehouse architecture is even simpler than traditional ones! :)
Shared Storage can be AWS S3 or Azure Blob Storage. The cloud handles it all. Just use a compute engine like Presto, and you have a perfect Cloud Warehouse, right?
Here’s a real-world problem blocking the road to this ideal:
Shared Storage usually isn’t designed for low latency and high throughput. Occasional hiccups are also hard to control. Brute-forcing it with the compute engine doesn’t seem like a good product.
How to Design?
First, let’s look at the different data states in a Cloud Warehouse:
- Persistent data: Typically user data, heavily relying on Shared Storage
- Intermediate data: Usually temporary computation results, like those from sorting, JOIN, etc.
- Metadata: object catalogs, table schema, users, etc.
Since we assume Shared Storage is unreliable, let’s minimize reads from it. Add caching to solve this.
A new question arises: what exactly should the cache cache? Raw block data or indexes? A global cache or per-node cache?
Snowflake Architecture
Let’s first look at how Snowflake, the big brother, designs it:
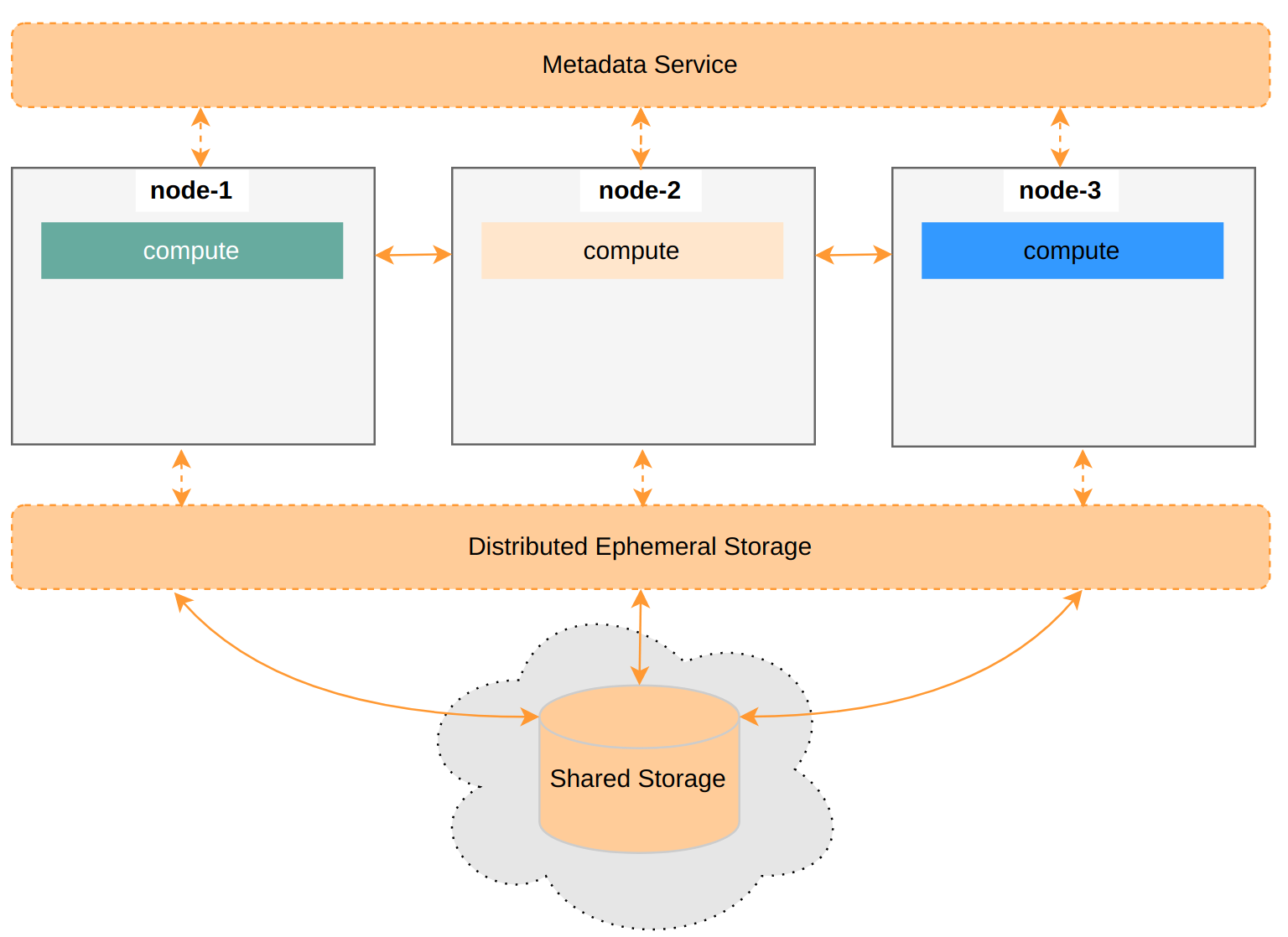
Snowflake adds a shared Ephemeral Storage between compute and storage, mainly for Intermediate data storage while also serving as a Persistent data cache. The benefit is full cache utilization. The downside is that making this Distributed Ephemeral Storage elastic faces challenges, like resource isolation in multi-tenant scenarios.
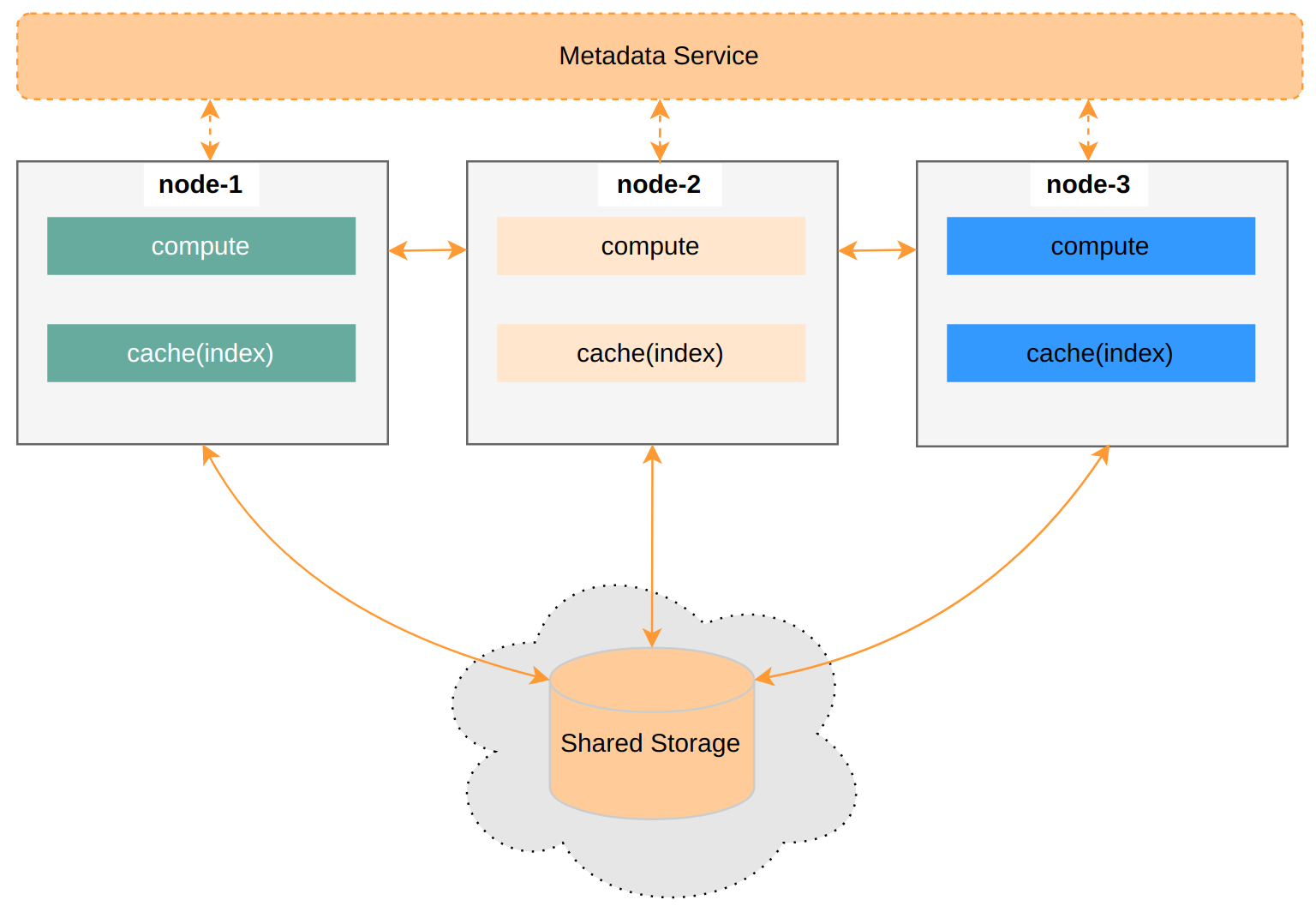
Datafuse Architecture
Cloud Warehouse emphasizes state separation. We can pre-generate plenty of indexes for Persistent data and place them in the Metadata Service. Each compute node subscribes and updates its local cache as needed. This architecture is similar to Firebolt.
This is the simplest viable approach currently. Adding a compute node only requires warming up the cache. It also faces challenges, like quickly syncing massive index information.
Summary
Databend is an open-source Cloud Warehouse that focuses on compute-state separation and elastic scaling in the cloud, making it easy to build your own Data Cloud.
I’m excited to start a new series on Databend — a warehouse project that connects Rust and Cloud, full of fun and challenges.
